
分析下面这行代码的运行过程:
BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource(“beanFactoryTest.xml”));
在XMLBeanFactory构造方法XmlBeanFactory(Resource resource):
@Deprecated@SuppressWarnings({"serial", "all"})public class XmlBeanFactory extends DefaultListableBeanFactory { private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this); public XmlBeanFactory(Resource resource) throws BeansException { this(resource, null); } public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException { super(parentBeanFactory); this.reader.loadBeanDefinitions(resource); }} 跟着this.reader.loadBeanDefinitions(resource);进入XmlBeanDefinitionReader类型的reader属性提供的loadBeanDefinitions(Resource resource)方法.this.reader.loadBeanDefinitions(resource);这行代码是整个资源加载的切入点,先来看一下调用时序图:
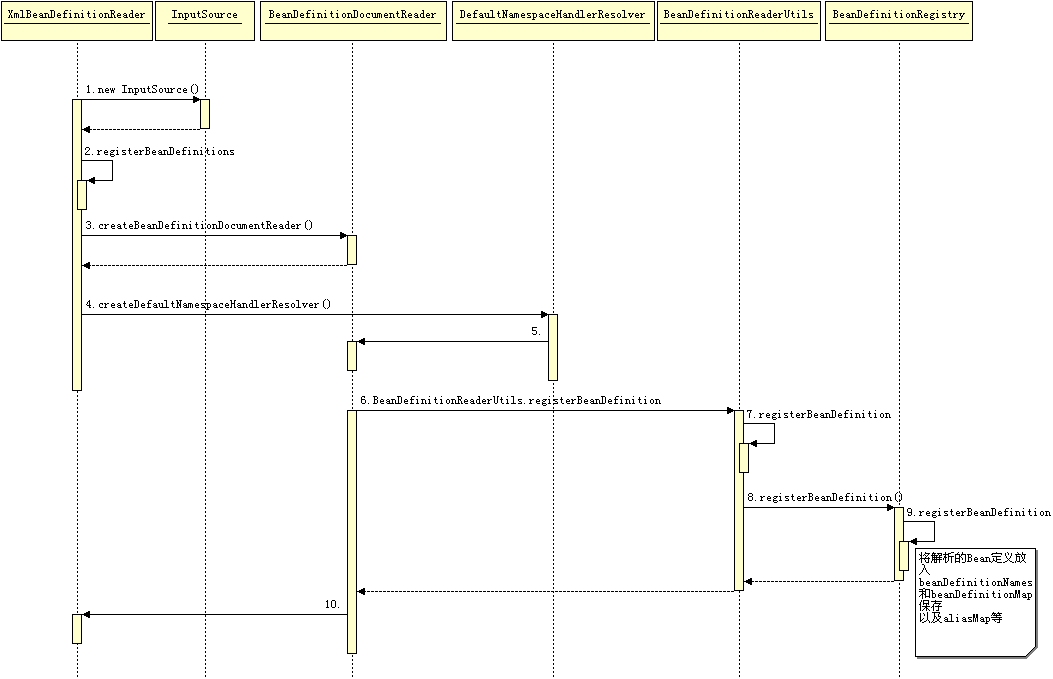
从上面时序图中可以得知,在加载XML文档和解析注册Bean,一直在做准备工作.依据上面的时序图来分析一下这里究竟在做什么准备?
封装资源文件.当进入XmlBeanDefinitionReader后首先对参数Resource使用EncodedResource类进行封装
获取输入流.从Resource中获取对应的InputStream并构造InputSource. 通过构造的InputSource实例和Resource实例继续调用函数doLoadBeanDefinitions 接下来看一下loadBeanDefinitions函数具体的实现过程:@Overridepublic int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException { return loadBeanDefinitions(new EncodedResource(resource));} 其中EncodedResource的作用:对资源文件的编码进行处理.其中的主要逻辑体现在getReader方法中,当设置了编码属性的时候Spring会使用相应的编码作为输入流的编码.其中getReader方法如下: public Reader getReader() throws IOException { if (this.charset != null) { return new InputStreamReader(this.resource.getInputStream(), this.charset); } else if (this.encoding != null) { return new InputStreamReader(this.resource.getInputStream(), this.encoding); } else { return new InputStreamReader(this.resource.getInputStream()); }} 上面的代码中构造了一个由编码(encoding)的InputStreamReader.当构造好EncodedResource对象后,再次转入了可复用方法loadBeanDefinitions(EncodedResource encodedResource). 这个方法内部才是真正的数据准备阶段,也就是时序图所描述的逻辑:
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException { Assert.notNull(encodedResource, "EncodedResource must not be null"); if (logger.isInfoEnabled()) { logger.info("Loading XML bean definitions from " + encodedResource.getResource()); } // 通过属性来记录已经加载的资源 Set currentResources = this.resourcesCurrentlyBeingLoaded.get(); if (currentResources == null) { currentResources = new HashSet (4); this.resourcesCurrentlyBeingLoaded.set(currentResources); } if (!currentResources.add(encodedResource)) { throw new BeanDefinitionStoreException("Detected cyclic loading of " + encodedResource + " - check your import definitions!"); } try { // 从EncodedResource中获取已经封装的Resource对象并再次从Resource中获取其中的inputStream InputStream inputStream = encodedResource.getResource().getInputStream(); try { // InputSource这个类并不是来源于Spring,他的全路径为:org.xml.sax.InputSource InputSource inputSource = new InputSource(inputStream); if (encodedResource.getEncoding() != null) { inputSource.setEncoding(encodedResource.getEncoding()); } // 真正进入了逻辑核心服务 return doLoadBeanDefinitions(inputSource, encodedResource.getResource()); } finally { inputStream.close(); } } catch (IOException ex) { throw new BeanDefinitionStoreException( "IOException parsing XML document from " + encodedResource.getResource(), ex); } finally { currentResources.remove(encodedResource); if (currentResources.isEmpty()) { this.resourcesCurrentlyBeingLoaded.remove(); } }} 整理一下上面的逻辑:首先对resource参数做封装,目的是考虑到Resource可能存在编码要求的情况,其次,通过SAX读取XML文件的方式来准备InputSource对象,最后将准备的数据通过参数传入真正的核心处理部分doLoadBeanDefinitions(inputSource, encodedResource.getResource()).其中doLoadBeanDefinitions(inputSource, encodedResource.getResource())方法实现如下: protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) throws BeanDefinitionStoreException { try { Document doc = doLoadDocument(inputSource, resource); return registerBeanDefinitions(doc, resource); } catch (BeanDefinitionStoreException ex) { throw ex; } catch (SAXParseException ex) { throw new XmlBeanDefinitionStoreException(resource.getDescription(), "Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex); } catch (SAXException ex) { throw new XmlBeanDefinitionStoreException(resource.getDescription(), "XML document from " + resource + " is invalid", ex); } catch (ParserConfigurationException ex) { throw new BeanDefinitionStoreException(resource.getDescription(), "Parser configuration exception parsing XML from " + resource, ex); } catch (IOException ex) { throw new BeanDefinitionStoreException(resource.getDescription(), "IOException parsing XML document from " + resource, ex); } catch (Throwable ex) { throw new BeanDefinitionStoreException(resource.getDescription(), "Unexpected exception parsing XML document from " + resource, ex); }} 忽略掉上面的异常处理部分,上面的代码只做了三件事情: 获取对XML文件的验证模式
加载XML文件,并得到对应的Document. 根据返回的Document注册Bean信息. 上面的三个步骤支撑着整个Spring容器部分的实现基础.